(この記事はLISP Implementation Advent Calendar 7日目のためのエントリです。)
NekoとTclでLISPを作りました。
https://github.com/zick/NekoLisp
https://github.com/zick/TcLisp
動機
今年の春、訳あって42個のプログラミング言語でLISP処理系を実装することになりました。これはその9〜10個目です。
Nekoを選んだ理由はよく覚えていませんが、たしかWikipediaを眺めていて名前が可愛かったから選んだという感じだったかと思います。
Tclを選んだ理由は簡単な予感がしたのと、このマンガがいい感じだったからです。
Nekoの思い出

外観
見るからにイマドキの言語ですぐ書けそうです。
var makeCons = function(a, d) {
return { tag => "cons", car => a, cdr => d }
}
こりゃどう考えても簡単だ。
マニュアル分からん
でもライブラリ関数を使おうとしたところでいきなりつまづきました。たぶん、何かを import やらなんやらしないといけない、というのはすぐに予想がついたんですが、いくらマニュアルを探しても分からない。仕方がないからぐぐってみたものの、マイナー言語故にあまり資料が見つかりませんでした。頑張って色々調べた末に、
var buffer_add = $loader.loadprim("std@buffer_add", 2);
こんなふうに書けばいいと分かりました。この 2 は引数の数。なんでマニュアルに載ってる関数使うために、FFIを使うみたいな真似をしないといけないとは。いや、それはいいとして、せめてマニュアルの分かりやすいところに書いてください。
謎の『$』
Nekoの一部の組み込み関数は $print という風に先頭に $ が付きます。すべての関数に $ が付くのなら分かりやすいのですが、一部にのみ付くので、頻繁に付け忘れました。なんとかして欲しいです。
スクリプト言語?
Nekoのマニュアルをいくら探しても標準入力から1行とってくる、という関数が見つかりませんでした。しかたがないので自分で実装するはめに。
var readline = function() {
var stdin = file_stdin()
var buf = buffer_new()
try {
while (true) {
var c = file_read_char(stdin)
if (c == 0x0a) {
break;
}
buffer_add_char(buf, c)
}
} catch e {
return false
}
return buffer_string(buf)
}
なんでスクリプト言語で readline なんつーものを自分で実装しないといけないんですか。やめてください。
再帰不能
Nekoでは素直に関数の再帰呼び出しを行うことができないようです。
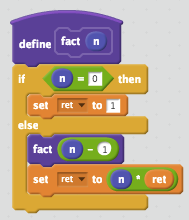
var fact = function(n) {
if (n == 0) {
return 1
}
return n * fact(n - 1) // Uncaught exception - Invalid call
}
なんと例外を投げます。どうやら function の内側からは fact が見えないようです。
var fact = null
fact = function(n) {
if (n == 0) {
return 1
}
return n * fact(n - 1) // Uncaught exception - Invalid call
}
こんな風に書きなおしても駄目。内側の fact は null になってしまいます。関数を定義し終えた後に変数を書き換えても元の値が使われてしまうようです。
では変数を書き換えなければいいのだろうということで、オブジェクトを作ってそのフィールドに関数を入れることで解決。
var fact = $new(null)
fact.call = function(n) {
if (n == 0) {
return 1
}
return n * fact.call(n - 1)
}
またどこかで聞いたような解決策に。
Tclの思い出

外観
パッと見たところ、割と普通の言語に見えます。
proc skipSpaces {str} {
set i 0
while {$i < [string length $str]} {
if {![isSpace $str $i]} {
break
}
incr i
}
return [string range $str $i [string length $str]]
}
でもよく見てみると、やたらと大括弧[]が多いことに気付きます。これこそがTclの(私にとって)面白いところです。
コマンド
Tclのプログラムは「コマンド」と引数の並びです。コマンドとは先程のプログラムだと set とか while とかです(実は proc もコマンドですが)。大事なルールは「引数は基本的に評価されない」ということです。 set i 0 の i は評価されずに名前のまま残るからこそ、 変数iに 0 が代入されるわけです。 incr i も同様に変数iがインクリメントされるわけです。
引数に現れる変数を評価したければ変数名の前に $ を付けます。しかし、これは変数のみを評価するのであって、引数全体を評価するものではありません。例えば string length $str というプログラムは $str の部分は変数の値に評価されますが、 length という部分はそのまま名前として残ります。結果として、 string というコマンドに length という名前と変数strの値が渡されます。実行結果は変数strの値である文字列の長さになります。lengthはコマンドstringのサブコマンドとでもいったところでしょうか。
コマンド置換
引数を評価したければ、大括弧を使います。例えば set i [string length $str] とすると、iに文字列の長さが代入されます。大括弧で囲まれた部分はコマンドとみなされ、それが先に実行されて、その実行結果で引数が置き換えられるので「コマンド置換」などと言うらしいです。シェルスクリプトのバックスラッシュみたいなものと考えれば分かりやすいかもしれませんが、なんだか品がありませんし、何よりも面白くありません。
ここで考え方を変えて、「Tclのプログラムは全体が quote されていて、大括弧で unquote される」と考えてみてください。Tclのプログラムが急に美しい世界に見えてきます。初めてLISPのquoteを知った時のような興奮が押し寄せてきます。何を評価して何を評価しないかは人に委ねるのではなく自分で決めるんだと考えると興奮のあまり鼻血が出てきそうになってきます。
リスト
Tclにはリストがあります。「そりゃリストくらいあるだろ」とお思いかも知れませんが、「リストは中括弧{}で表す」と聞くと、なにか大変なことに気付きませんか。そうです。ifやwhileの後に現れる中括弧、さらにはprocの後に現れる中括弧はなんとリストだったのです。Tclはすべてが quote されているのですから、リストもquoteされたリストです。つまり、リストで「その場では実行されないプログラム」を表現できるわけです。procやifやwhileはその引数を必要な場合に適切に評価するわけです。つまりスペシャルフォームです。もはやTclのプログラムは美しい花畑に見えてきて、その世界にいるだけで幸せな気分になってきます。「そもそもスペシャルフォームの存在が美しくない」という純粋すぎる方は専門の医師の診断を受けたほうがいいかもしれません。
expr
前述のプログラムをしっかりと読んだ人は $i < [string length $str] や ![isSpace $str $i] という箇所はコマンド+引数の形になっていないと気づいたかもしれません。「美しい世界など幻想。所詮は汚いスクリプト言語だ。」と思ったら大間違いです。
Tclには expr というコマンドがあります。これは引数を式とみなしてその値を求めるものです。
expr 1 + 2 # => 3
set i [expr 1 + 2] # iに3が代入される
string length "abcd" # => 4
expr $i < [string length "abcd"] # => 1 (Tclで1は真の扱い)
もうお分かりですね。ifやwhileの第一引数として受け取ったリストは expr に渡されるわけです。スペシャルフォームの枠組みからは出ておらず、十分に美しい世界の中の話といえるでしょう。興奮冷め止まない感じです。
TclでLISP
さて、そろそろLISPを作った話をします。普段ならその言語にどんなデータ構造があってどうやったら楽に書けそうかを考えるんですが、すっかり興奮しきったは私はLISPを書きたい欲求を抑えきれず「もう整数だけあればいいや」とまるでCで書くようなLISPを書いてごみ集めも自分で書いてしまいました。
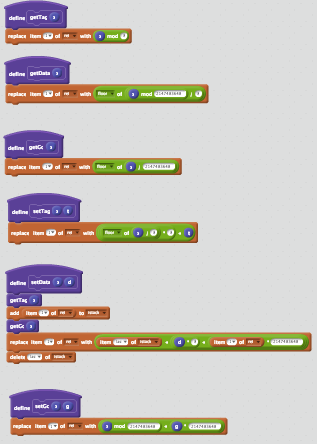
# <Object>
# MSB LSB
# gc(1) data(28) tag(3)
proc getTag {x} {
return [expr {$x & 0x7}]
}
proc setData {x data} {
return [expr {($x & ~0x7ffffff8) | (($data << 3) & 0x7fffffff)}]
}
基本的にScratchのときと同じ実装です。ただ、マウスではなくキーボードでプログラムを書けるのであまりにも簡単でした。キーボードの神様に感謝。
小学生並みの感想
キーボードでプログラムを書けるって素晴らしい。