[LSP42] ドキッ!LISPだらけの大運動会
木曜日, 12月 25th, 2014(この記事はLISP Implementation Advent Calendar 25日目のためのエントリかもしれません。)
背景
今年の春、訳あって42個のプログラミング言語でLISP処理系を実装しました。ソースコードはすべてGitHub上においてます。作り終えたらやりたくなることは一つ。そう、速度の比較ですね。そんなわけで42個のLISP処理系の速度を計測しました。言語によって100倍以上の速度差があるため、すぐ終わるベンチマークでは速い言語同士の比較ができず、時間のかかるベンチマークだと遅い言語が終わらないため、3種類のベンチマークを用意して速度を比べました。計測には time コマンドの total を使用し、各言語3回の計測を行い、その中間値を使用しました。ハッキリ言っていい加減な値なので、きちんとした結果を知りたい人は各自42個の言語処理系を用意して計測しなおしてください。
なお、この記事はクリスマスが暇で仕方ない人向けに必要以上に水増しして長くしてあるので、暇でない方は最後だけ読まれることをおすすめします。

一回戦
最初のベンチマークは相互再帰によるフィボナッチ数の計算。 (fib 15) の実行時間を測りました。
((lambda(x) (defun fib (n) (if (eq n 1) 1 (if (eq n 0) 1 (+ (fib(- n 1)) (fib(- n 2)))))) (fib x)) 15)
計算自体は一瞬で終わる言語が多いため、実質的に起動時間のベンチマークといえるかもしれません。一部の言語処理系は起動に2秒以上かかるので、それにより大きく順位を落としています。
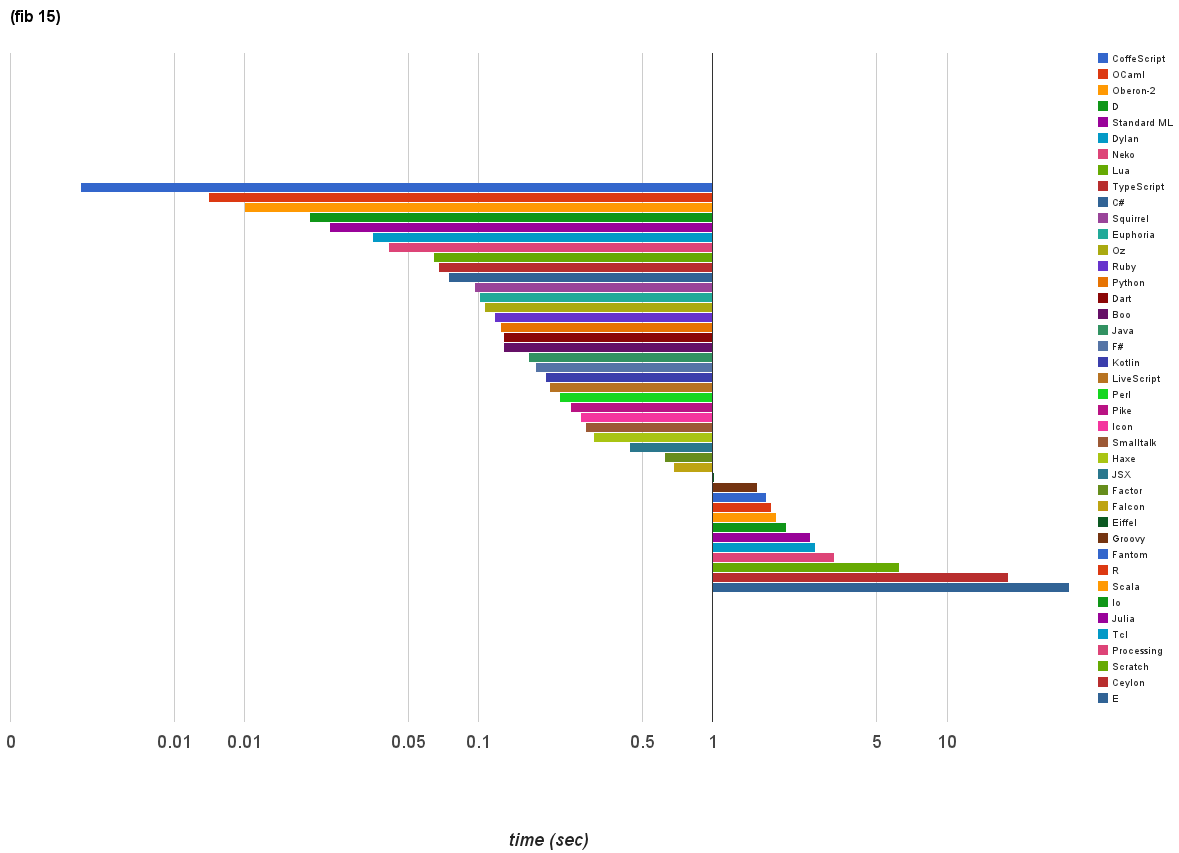
対数グラフであることに注意してください。
トップはCoffeScriptの0.002秒。続いてOCamlの0.007秒。そして3位はなんとOberon-2の0.01秒です。
最下位はEの33.311秒、そしてCeylonの18.358秒、Scratchの6.25秒が続きます。
Scratchは起動時間を含んでいませんが、それでもCeylonとEより速いのは明らかです。これには業界のアナリストも苦笑いでしょうか。
目がいい人はグラフに41言語しかないことに気づいたかもしれません。これはIokeがスタックオーバフローを引き起こし計算を最後まで出来なかったためです。スタックサイズを増やす方法を調べたのですが見つからなかったので諦めました。
二回戦
次のベンチマークも相互再帰によるフィボナッチ数の計算。 (fib 15) の実行時間を測りました。ただし、LISPで書かれたLISP評価器の上で計算を行います。
つまり、ある言語の上でLISP処理系が動き、そのLISP処理系の上でLISP評価器が動き、その上でフィボナッチ数の計算を行います。
((lambda (ge) (setq #+nil (defun funcall (f x) (f x))) (defun mcon% (a d) (lambda (c) (if (eq c 'car) a (if (eq c 'cdr) d (if (eq (car c) 'car) (setq a (cdr c)) (if (eq (car c) 'cdr) (setq d (cdr c)))))))) (setq ge (mcon% (mcon% (mcon% 't 't) ()) ())) (defun cadr% (x) (car (cdr x))) (defun cddr% (x) (cdr (cdr x))) (defun assoc% (k l) (if l (if (eq k (funcall (funcall l 'car) 'car)) (funcall l 'car) (assoc% k (funcall l 'cdr))) ())) (defun fv% (k a) (if a ((lambda (r) (if r r (fv% k (funcall a 'cdr)))) (assoc% k (funcall a 'car))) ())) (defun ea% (e a) ((lambda (b) (if b (funcall b 'cdr) e)) (fv% e a))) (defun el% (e a) (cons '%e% (cons (car e) (cons (cdr e) a)))) (defun ae% (s v) (funcall ge (cons 'car (mcon% (mcon% s v) (funcall ge 'car)))) s) (defun eval% (e a) (if (atom e) (ea% e a) (if (eq (car e) 'quote) (cadr% e) (if (eq (car e) 'if) (if (eval% (cadr% e) a) (eval% (cadr% (cdr e)) a) (eval% (cadr% (cddr% e)) a)) (if (eq (car e) 'lambda) (el% (cdr e) a) (if (eq (car e) 'defun) (ae% (cadr% e) (el% (cddr% e) a)) (if (eq (car e) 'setq) ((lambda (b v) (if b (funcall b (cons 'cdr v)) (ae% (cadr% e) v)) v) (fv% (cadr% e) a) (eval% (cadr% (cdr e)) a)) (apply% (eval% (car e) a) (evlis% (cdr e) a))))))))) (defun pairlis% (x y) (if x (if y (mcon% (mcon% (car x) (car y)) (pairlis% (cdr x) (cdr y))) ()) ())) (defun evlis% (l a) (if l (cons (eval% (car l) a) (evlis% (cdr l) a)) ())) (defun progn% (l a r) (if l (progn% (cdr l) a (eval% (car l) a)) r)) (defun apply% (f a) (if (eq (car f) '%e%) (progn% (cadr% (cdr f)) (mcon% (pairlis% (cadr% f) a) (cddr% (cdr f))) ()) (if (eq (car f) '%s%) (funcall (cdr f) a) f))) (defun es% (e) (if (atom e) e (if (eq (car e) '%s%) '
読みやすい形のLISP評価器はGitHubにおいてあります。
https://github.com/zick/ZickStandardLisp/blob/master/lisp.lsp
今回はそれなりに時間がかかるため純粋に速さの勝負となります。また、リスト操作が非常に多いためコンスセルの実装方法も速度に大きな影響を与えそうです。
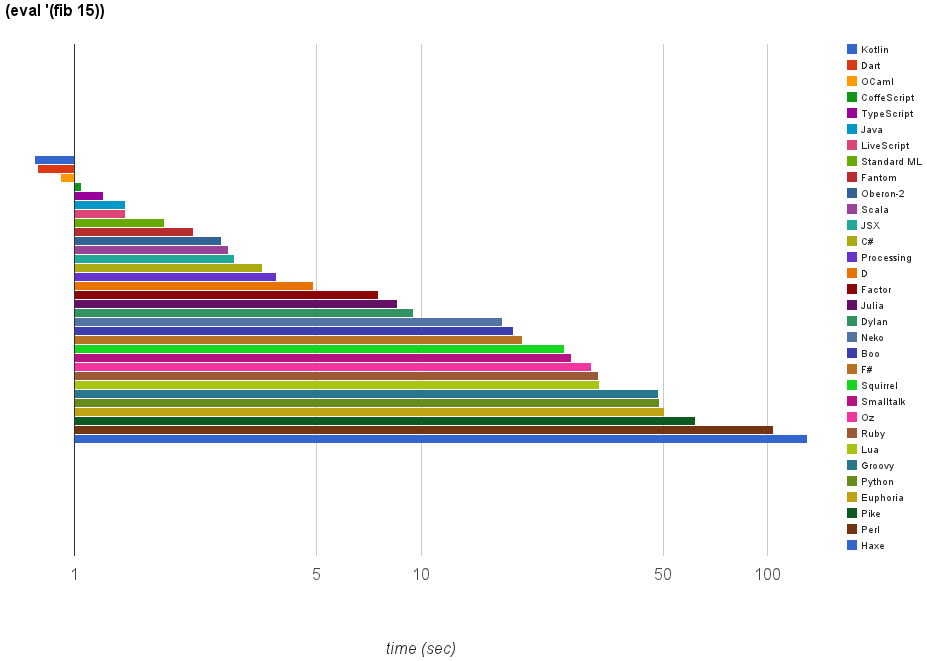
これも対数グラフなので注意してください。
トップはKotlinの0.764秒。続いてDartの0.782秒。そしてOCamlの0.91秒が続きます。KotlinはJVMで動く言語ですがJavaを大きく引き離しているのが印象的です。JavaScript系の言語はどれも好成績を収めていますが、その中でも独自のVMを使うDartが他の言語を一歩上回りました。OCamlはStandard MLを倍近く引き離しました。F#ははるか後ろですがこれは私の実装方法が悪かったせいかもしれません。
最下位はHaxeの130.88秒。そしてPerlの104.08秒、Pikeの62.23秒が続きます。PerlやPikeのように型が柔軟な言語が後ろの方に来るのはある程度しかたがないことかもしれませんが、ガチガチに型を書いたHaxeがこうも遅いと悲しくなります。
なお、R、Icon、Ioke、Eはスタックオーバフローのため計測できず。Scratch、Io、Tcl、Falcon、Ceylon、Eiffelは5分以内に終わらなかったので打ち切りました。
決勝戦
最後のベンチマークも相互再帰によるフィボナッチ数の計算。 (fib 15) の実行時間を測りました。ただし、LISPで書かれたLISP評価器の上で動く、LISPで書かれたLISP評価器の上で計算を行います。
つまり、ある言語の上でLISP処理系が動き、そのLISP処理系の上でLISP評価器が動き、そのLISP評価器の上でLISP評価器が動き、その上でフィボナッチ数の計算を行います。
((lambda (ge) (setq #+nil (defun funcall (f x) (f x))) (defun mcon% (a d) (lambda (c) (if (eq c 'car) a (if (eq c 'cdr) d (if (eq (car c) 'car) (setq a (cdr c)) (if (eq (car c) 'cdr) (setq d (cdr c)))))))) (setq ge (mcon% (mcon% (mcon% 't 't) ()) ())) (defun cadr% (x) (car (cdr x))) (defun cddr% (x) (cdr (cdr x))) (defun assoc% (k l) (if l (if (eq k (funcall (funcall l 'car) 'car)) (funcall l 'car) (assoc% k (funcall l 'cdr))) ())) (defun fv% (k a) (if a ((lambda (r) (if r r (fv% k (funcall a 'cdr)))) (assoc% k (funcall a 'car))) ())) (defun ea% (e a) ((lambda (b) (if b (funcall b 'cdr) e)) (fv% e a))) (defun el% (e a) (cons '%e% (cons (car e) (cons (cdr e) a)))) (defun ae% (s v) (funcall ge (cons 'car (mcon% (mcon% s v) (funcall ge 'car)))) s) (defun eval% (e a) (if (atom e) (ea% e a) (if (eq (car e) 'quote) (cadr% e) (if (eq (car e) 'if) (if (eval% (cadr% e) a) (eval% (cadr% (cdr e)) a) (eval% (cadr% (cddr% e)) a)) (if (eq (car e) 'lambda) (el% (cdr e) a) (if (eq (car e) 'defun) (ae% (cadr% e) (el% (cddr% e) a)) (if (eq (car e) 'setq) ((lambda (b v) (if b (funcall b (cons 'cdr v)) (ae% (cadr% e) v)) v) (fv% (cadr% e) a) (eval% (cadr% (cdr e)) a)) (apply% (eval% (car e) a) (evlis% (cdr e) a))))))))) (defun pairlis% (x y) (if x (if y (mcon% (mcon% (car x) (car y)) (pairlis% (cdr x) (cdr y))) ()) ())) (defun evlis% (l a) (if l (cons (eval% (car l) a) (evlis% (cdr l) a)) ())) (defun progn% (l a r) (if l (progn% (cdr l) a (eval% (car l) a)) r)) (defun apply% (f a) (if (eq (car f) '%e%) (progn% (cadr% (cdr f)) (mcon% (pairlis% (cadr% f) a) (cddr% (cdr f))) ()) (if (eq (car f) '%s%) (funcall (cdr f) a) f))) (defun es% (e) (if (atom e) e (if (eq (car e) '%s%) '
非常に時間が掛かることが予想されたため、二回戦の上位8言語に対してのみ計測を行いました。
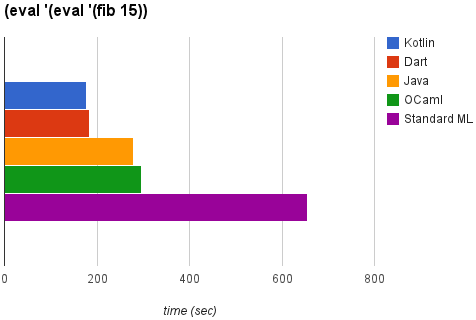
今回は対数グラフではありません。
まずはじめに、V8上で動くCoffeScript、TypeScript、LiveScriptの3言語はスタックオーバフローため最後まで走り切ることができませんでした。
Standard MLは無事最後まで走り切ることができましたが、654.27秒というイマイチな記録。
OCamlはStandard MLの倍以上速い296.88秒という記録でこれに続きました。
3位はJava。記録は279.96秒。JVMで動く言語が多数あるなか本家が良い記録を残しました。
2位はDart。記録は184.57秒。3位を大きく引き離しました。
そして栄えある1位はKotlin。記録は177.09秒。JVM上で動く新しい言語が42言語の頂点に立ちました。

あらためてKotlinの思い出
作っていた時の感触から、Dart、[Coffee,Type,Live]Script、Standard ML、OCamlあたりが上位に行くことはなんとなく分かっていました。また、JavaがJVMの力により上位に来ることも予想していました。しかし、Kotlinが1位はおろか、上位に来ることさえ予想していませんでした。
KotlinでLISPを実装した時に私は次のようなメモを書き残していました。
2014-06-29
Kotlin
コンパイルして実行する方法が分からず長時間時間以上悩む。IDEの使い方しか載ってないような言語は等しく灰に還ればいいのに。whileとisの組み合わせがちょっと冗長。型を間違えると、お前は昔のC++かと言いたくなるくらい、怒涛の勢いでエラーを出す。言語としては悪く無いと思うけど、コマンドラインからの実行方法が書いてなくて悩んだせいで心象が悪い。
そう。思い返してみるとコマンドラインから実行する方法を見つけるまで非常に時間がかかり、ものすごく心象が悪かったんです。6月末に実装したわけですが、12月に時点では「ああ、IDEの使い方しか載ってなかった言語か」という程度しか覚えておらず、速かったか遅かったかなどまったく覚えていなかった訳です。
ちなみに「whileとisの組み合わせ」というのはこれです。
fun nreverse(l : Any) : Any {
var lst = l
var ret : Any = kNil
while (true) {
val elm = lst
if (elm is Cons) {
val tmp = elm.cdr
elm.cdr = ret
ret = lst
lst = tmp
} else {
break
}
}
return ret
}
本当は while (lst is Cons) のように書きたいのですが、それが許されていないためネストも深くなるしコードも冗長になってしまいます。これはなんとか改善して欲しいですね。
KotlinとJava、どうして差がついたのか…慢心、環境の違い
同じJVMで動くKotlinとJavaでどうしてこうも差がついたのでしょうか。Kotlinのコンパイラがものすごい賢いコードを出力するのでしょうか。その可能性もなくは無いでしょうが、主な原因はコンスセルの表現の違いでしょう。Javaでは気まぐれで次のようにコンスセルを表現しました。
enum Type {
NIL, NUM, SYM, ERROR, CONS, SUBR, EXPR,
}
class LObj {
public Type tag() { return tag_; }
public LObj(Type type, Object obj) {
tag_ = type;
data_ = obj;
}
public Cons cons() {
return (Cons)data_;
}
....
private Type tag_;
private Object data_;
}
class Cons {
public Cons(LObj a, LObj d) {
car = a;
cdr = d;
}
public LObj car;
public LObj cdr;
}
コンスもシンボルもLObjという一種類のクラスで表現し、data_フィールドに実体を入れて、型はtag_を見て判断します。どうしてこの実装にしたかの詳しい経緯は12/24の記事を読んでください。詳しくない経緯は「気まぐれ」です。さて、この実装でコンスのCAR部を取り出そうとすると、次のようなバイトコード(もしくはそれをJITコンパイルしたもの)が実行されます。
aload_0 // 対象のオブジェクトをスタックに置く invokevirtual LObj.tag // tag()を呼び、tag_をスタックに置く getstatic Type.CONS // CONSをスタックに置く if_acmpne // tag_がCONSでなければ(どこかに)ジャンプ aload_0 // 再度、対象のオブジェクトをスタックに置く invokevirtual LObj.cons // cons()を呼び、data_をスタックに置く getfield Cons.car // CAR部を取り出す
consメソッドはこんな感じです。
aload_0 // 引数をスタックに置く getfield data_ // data_フィールドをスタックに置く checkcast Cons // data_の型がConsか確認(異なれば例外を投げる) areturn // data_を返す
一方、Kotlinではコンスセルを次のように表現しました。
class Cons(a : Any, d : Any) {
var car = a
var cdr = d
}
そのままです。型を見るときには前述した is を使います。この実装でコンスセルのCAR部を取り出そうとすると、次のようなバイトコード(もしくはそれをJITコンパイルしたもの)が実行されます。
aload_0 // 対象のオブジェクトをスタックに置く instanceof Cons // 型がConsなら1、異なれば0をスタックに置く ifeq // 0なら(どこかに)ジャンプ aload_0 // 再度、対象のオブジェクトをスタックに置く checkcast Cons // オブジェクトの型がConsか確認(異なれば例外を投げる) invokevirtual Cons.getCar // getCarを呼ぶ
getCarはKotlinが自動生成するメソッドで、次のようになります。
aload_0 // 引数をスタックに置く getfield car // carを取り出す areturn // carを返す
Kotlinの方が短いですね。細かな違いはJITコンパイルされると消えてしまうかもしれませんが、(恐らく)消えないのは getfield data_ でしょう。Javaはどうあがいても2回参照をたどらないとCARにたどり着けません。一方Kotlinは一回の参照でCARにたどり着けます。何度もリスト操作を繰り返す今回のベンチマークではこれが大きな差を産んだのではないでしょうか。
と、仮説だけを書いているといろんな人に怒られそうなので、実際に検証してみました。
こちらはJavaのプロファイル結果。

findVarが一番時間をくっているというのは環境に連想リストを使っているので当然の結果ですね。注目すべき点は cons() が二番目というところです(どうしてこのメソッドがこんなに遅いか調べるのは読者の練習問題とします)。それ以降にもリスト関連のメソッドが並んでいます。
次はKotlinのプロファイル結果。
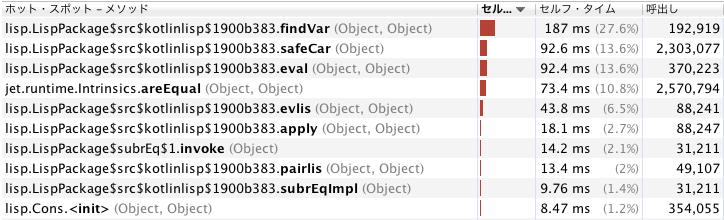
findVarが一番時間をくっているのはJavaと同じですが、当然ながら cons() に相当するものがありません。それからJavaのmakeConsよりKotlinのCons.<init>が速いというのもポイントですね。考えてみたらJavaはLObjとConsの2つのオブジェクトを作るのに対し、Kotlinは単一のオブジェクトしか作らないのでこれも当然ですね。
この結果を見る限り、やはりコンスの実装の違いが実行時間に影響を与えているようです。
では、ここでひとつの疑問が出てきます。Javaの実装をKotlinと同じようにすればどちらが速いのか。これは読者の練習問題とします。
父兄の皆様へ
「うちの
小学生並みの感想
Kotlinが一番速かったです。













