[LSP42] Factor
金曜日, 12月 5th, 2014(この記事はLISP Implementation Advent Calendar 5日目のためのエントリです。)
FactorでLISPを作りました。
https://github.com/zick/FactorLisp

Factorはいわゆるスタック指向型のプログラミング言語です。Factorの開発元は concatenative programming という言葉を好んで使っているようですが、この言葉はあまりメジャーではない気がします。
動機
今年の春、訳あって42個のプログラミング言語でLISP処理系を実装することになりました。これはその7つ目です。
Factorを選んだ理由はよく覚えていないのですが、確かWikipediaを眺めてテキトーに決めたんだと思います。Lua、Python、Ruby、R、Perlといった有名な(少なくても私が名前を知っていた)言語が続いていたので変わったものをやりたいという気持ちもあったかもしれません。
スタック
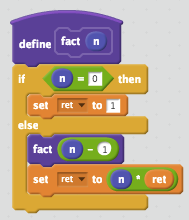
Factorでは 1 2 + とか書いたら1+2 が実行されます。1と2がスタックに積まれて可算が実行されるわけです。スタック特有の操作として最低限、スタックトップを捨てる drop, スタックトップをコピーする dup, スタックトップとその1つ下を入れ替える swap あたりを知っておくと便利です。階乗は次のように書けます。
: fact ( n -- m )
dup 0 = [
drop 1
] [
dup 1 - fact *
] if ;
最初のコロンはこれからワード(関数みたいなもの)の定義が始まりますよという印で、 fact はそのワードの名前。その後の括弧はコメントで実行結果には何も影響を与えません。 dup 以降の残りの部分は読者の練習問題とします。
さて、この括弧が面白いので解説すると ( n -- m ) は「スタックから1つものを消費して、スタックに1つものを置く」ということを表しています。例えば drop は ( x -- ), dup は ( x -- x x), swapは ( x y -- y x) という記法で表せます。前述のとおり、これらはコメントで実行結果には影響しませんが、Factorはコンパイル時にワードが実際にこのコメントと合致しているか確かめます。 if のようにコードが分岐する場合もスタックに置かれるものの数が変わらないかチェックしてくれるわけです。非常に親切です。
例えば
: wrong-fact ( n -- m )
dup 0 = [
drop 1
] [
1 - wrong-fact *
] if ;
こんなコードをコンパイルすると
The input quotations to “if” don't match their expected effects Input Expected Got [ drop 1 ] ( ..a -- ..b ) ( x -- x ) [ 1 - wrong-fact * ] ( ..a -- ..b ) ( x x -- x )
といった具合に非常に分かりやすいエラーメッセージを出してくれるわけです。
オブジェクト
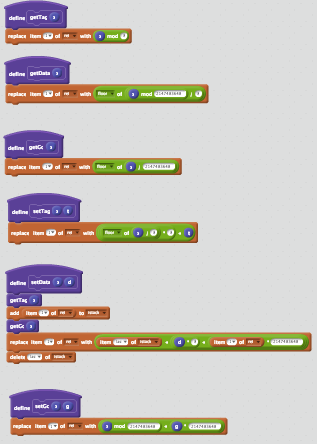
Factorはオブジェクト指向言語でもあります。総称関数(正確には generic word )を作れたり、色々と凄いんです。これでLISPのデータを定義してやれば色々と凄そうなわけです。でもまあ、LISPを作るくらいだとそんな高度な機能も必要ありませんが。
TUPLE: lobj tag data ;
C: <lobj> lobj
TUPLE: cell car cdr ;
C: <cell> cell
: make-cons ( car cdr -- lobj )
<cell> "cons" swap <lobj> ;
: safe-car ( lobj -- lobj )
dup tag>> "cons" = [
data>> car>>
] [
drop kNil get-global
] if ;
これが何をしているかは明らかなのでコードの解説は読者の練習問題とします。
quotation と stack checker
FactorはLispの quote のようにコードをオブジェクトとして扱うことが出来ます。上記コードの if といっしょに現れる大括弧 [] で囲まれた部分がそれです。このようなオブジェクトを quotation と呼びます。 quotation があるおかげで、 if や while といったプリミティブが自然な形で使えるし、高階ワードを作ることもできるわけです。しかし、これには制約があります。
The stack checker cannot guarantee that a literal quotation is still literal if it is passed on the data stack to an inlined recursive combinator such as each or map
データスタック経由でリテラルの quotation を inlined recursive combinator に渡すと、それがリテラルであるかどうか stack checker は保証できないとか何とか。まあ、なんとなく言っていることが分かるような分からないような感じですが、要は下手に quotation を使うとコンパイルエラーになるということです。詳しくは、詳しい人に聞いてください。私は「よーし、高階ワードを作って抽象化しちゃうぞ!」と気軽な気持ちで quotation を使ったら数時間この制約に悩まされ、結局 quotation を使わない方向に逃げることになって後悔しました。
『3』 – スタックについての究極の疑問の答え
Factorのマニュアルには「変数に名前をつける機能とかあるから、別にすべてをスタックでやらなくてもいいよ」と書いてありましたが、今回はあえてすべてをスタックの上でやりきりました。色々と試行錯誤しているうちに一つのことに気付きました。
一度に触るのがスタックトップから3つまでだと非常に簡単にプログラムが書けるのに対して、スタックトップから4つ目以降を触わろうとすると非常にぎこちないプログラムになる。
こうなった原因の一つとして、Factorが提供する組み込みのワードはスタックトップから3つ目までを操作するものが多い、ということもあるでしょうが、そもそも4つを超えたあたりで人間には色々と辛い、というのがでかい気がします。Factorの元となったForthに対して偉い人が
The words PICK and ROLL are mainly useful for dealing with deep stacks. But the current trend in Forth programming is to avoid making the stack deeper than 3 or 4 elements.
A Beginner’s Guide to Forth by J.V. Noble
と言っているので世の中の真理ではないのかと勝手に思っておきます。
スタックは熱いうちに打て
一日で「ドリャ」っとFactorのプログラムを書き上げる場合は、スタックの状態がどうなってるか、ある程度頭のなかに残っているからいいんですが、数日、数カ月と経ってから再度プログラムを編集しようとすると、スタックがどうなっているのか頭から完全に抜けているので辛いです。回避策は、長いワードを作らないことと、やはり1度に3つまでしかスタックに積まないことでしょうか。この辺りは誰か詳しい人にでも聞いてください。
小学生並みの感想
スタックは楽しい。そして辛い。